Appearance
Endpoint Settings
Each endpoint has a Settings tab where you can configure processing behavior. The available settings depend on whether the endpoint is a publisher, subscriber, or both.
Post Receipt Replication Messages
Subscriber only
When enabled, delivery receipts produced by this subscriber are published to a replication topic. A publishing endpoint with a configured Receipt Save Action can then pick up these receipts and write them back to the source system (e.g. as a system log entry). This is useful for confirming delivery status back to the originating connector.
Receipts can be filtered at the publishing endpoint by Receipt Level — all receipts, just errors, or just successful ones.
Override Key Source
Subscriber only
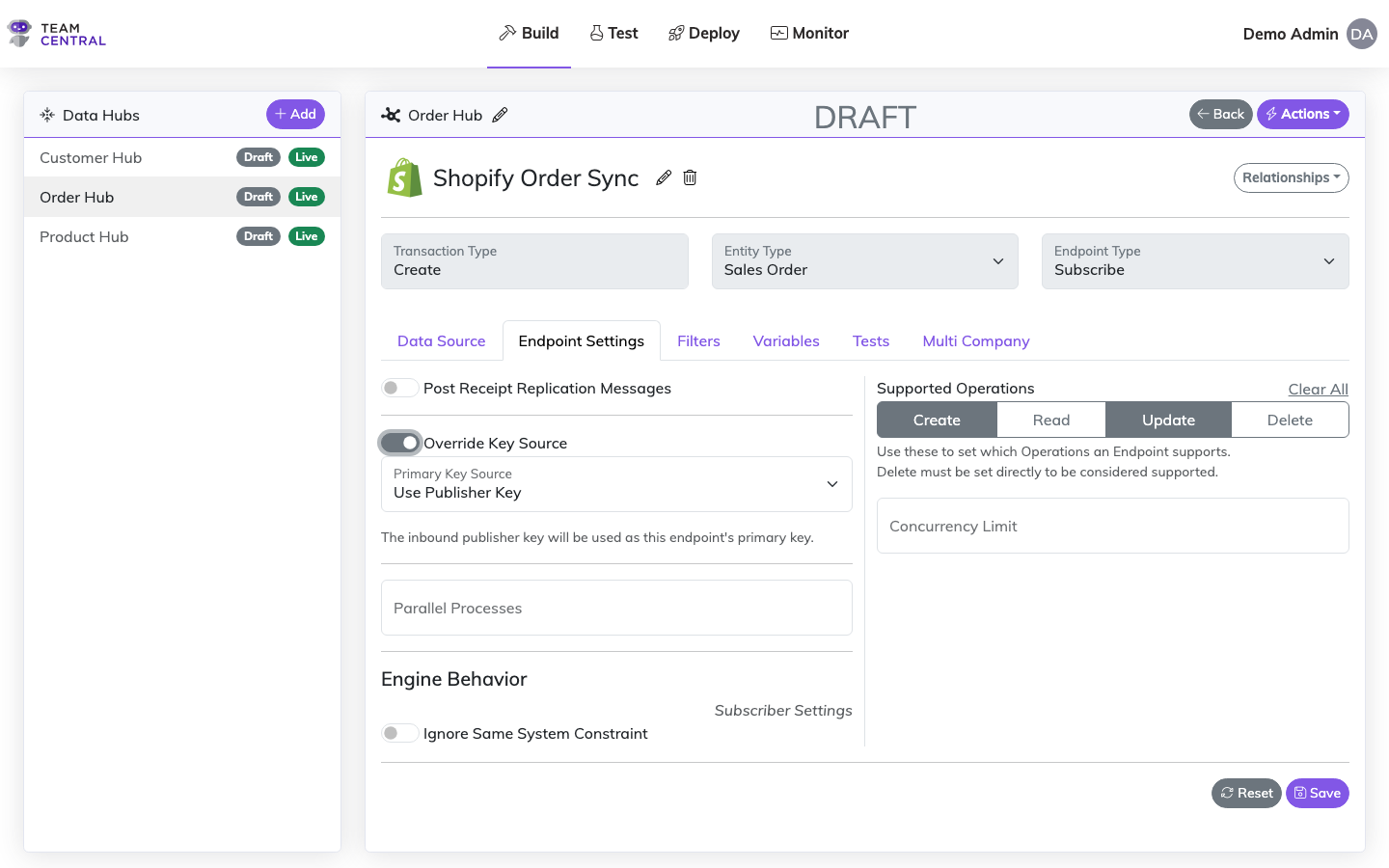
By default, a subscriber's primary key is derived from the engine's standard key resolution — typically an ObtainPrimaryKey action in the endpoint's save flow, or from previously accumulated keys on the indexed entity. The Override Key Source toggle lets you bypass that default and explicitly choose where the subscriber's primary key comes from.
When the toggle is off (default), key resolution follows the standard engine path. When toggled on, a Primary Key Source dropdown appears with two options:
Use Publisher Key
The subscriber uses the inbound message's publisher key (the source system's primary key) as its own primary key. This is useful when the subscriber system should store the same identifier that the publisher uses, eliminating the need for a separate key assignment step.
Use Model Property
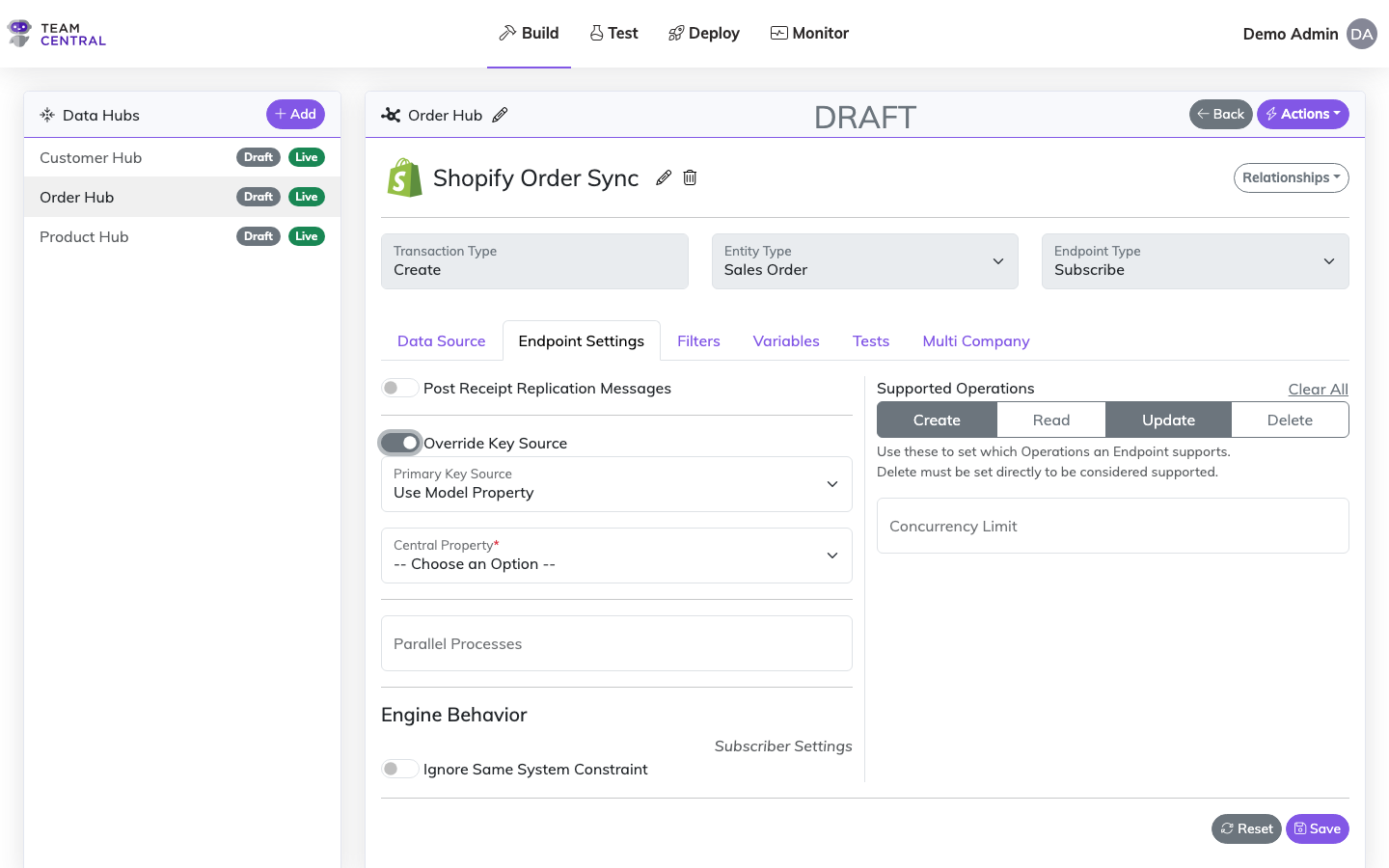
The subscriber derives its primary key from a property on the entity model. When selected, a property picker appears showing all simple (non-foreign-key) properties from the endpoint's Data Model. Select the property whose value should become the subscriber's primary key.
This supports both standard properties (via BusProperty) and custom data fields (via CommonName). The selected property map can also include transforms, so you can derive the key from a computed value.
When to use Override Key Source
Common scenarios:
- Publisher Key: When the subscriber should reuse the source system's ID (e.g. syncing a record back to a shared reference system)
- Model Property: When the subscriber's key comes from a business field like an order number, SKU, or external reference ID that exists on the entity model
WARNING
Override Key Source cannot be used alongside an ObtainPrimaryKey action targeting the same key (Id). If both are configured, a validation error will be raised on save.
Enable Property Change Tracking
Publisher only
When enabled, the publisher compares each new message against the most recently published message for the same entity. If none of the mapped properties have changed, the message is filtered out and not published. This prevents redundant downstream processing when an entity is re-read but its relevant data hasn't actually changed.
The comparison uses the endpoint's Read property maps to determine which fields to check. Only Save events are evaluated — Delete events are always published.
Parallel Process Count
Publisher and Subscriber
Controls the degree of parallelism when the endpoint processes messages. The engine uses this value as the MaxDegreeOfParallelism for message publishing and receipt processing operations.
- Defaults to 1 (sequential processing) when unset or
0 - Increase the count to process multiple messages concurrently, improving throughput for high-volume integrations
- Each parallel operation includes automatic retry logic (up to 10 retries)
- Higher values consume more system resources — increase gradually and monitor performance
Concurrency Limit
Subscriber only
Controls how many messages the Azure Service Bus processor can handle concurrently for this subscriber. Unlike Parallel Process Count (which controls parallelism within a processing batch), this setting governs how many messages the bus delivers to the subscriber at the same time.
Must be at least 1 if set. When left unset, the Service Bus default applies.
Supported Operations
Publisher and Subscriber
Defines which CRUD operations (Create, Read, Update, Delete) the endpoint supports. This controls which messages the endpoint will process or publish.
- When no operations are selected, the endpoint supports Create, Read, and Update by default
- Delete must be explicitly enabled — it is never implicitly supported, even when the list is empty. This is a safety mechanism to prevent accidental deletions
- For subscribers, the engine determines whether an incoming message is a Create or Update by checking if the entity already has a primary key for the subscriber's system
The same operation filtering is also applied at the map group and individual property map levels, allowing fine-grained control over which fields participate in each operation.
Supported Systems
When configured
Restricts the endpoint to only process messages from specific source systems. When the list is empty, all systems are accepted. Use this to limit which connected systems can publish to or subscribe from this endpoint.
Engine Behavior
Engine behavior settings control how the processing engine handles messages at a lower level. Publisher and subscriber settings are configured separately.
Subscriber Settings
Ignore Same System Constraint
By default, a subscriber will not process messages that originated from its own system. This prevents circular sync loops where a system receives its own changes back.
Enabling this setting bypasses that check, allowing the subscriber to process messages from its own system. Use this when you intentionally need a system to react to its own published changes.
Publisher Settings
Header Only
When enabled, the publisher only processes the header (parent) entity data. Child entity lists are not loaded from the database or merged from the integration message.
Use this when you only need to sync top-level entity fields and want to skip the overhead of processing child collections (e.g. line items, resources).
Skip Index
When enabled, the entity is not saved to the index after processing. The message is still published to subscribers, but no record is persisted locally.
This is useful for pass-through scenarios where you want to relay data downstream without maintaining a local copy.
Index Only
When enabled, the entity is saved to the local index but is not published to the subscriber topic. No downstream subscribers will receive the message.
Use this to build up the local entity index (e.g. during an initial data load) without triggering subscriber processing. Key accumulation is also skipped unless Send to Search is enabled.
Lookup Using All Primary Keys
When the engine cannot find an existing entity using the standard primary key, enabling this setting tells it to attempt a lookup using any other primary keys present in the message. This is a fallback mechanism — if the standard key doesn't match, the engine searches by alternate keys before deciding to create a new entity.
If multiple entities match the alternate keys, an error is thrown to prevent ambiguous updates.
Allow Multiple Primary Keys
This setting appears when Lookup Using All Primary Keys is enabled. It is configured per system — you toggle it on for each source system that should be allowed to store multiple primary keys on the same entity.
By default, each source system can only have one primary key per entity. If a new key arrives with a different ID for the same system, the engine either updates the existing key (if the key allows changes) or throws an error. When this setting is enabled for a system, additional keys with different IDs are added alongside existing ones instead of replacing them.
Allowed Trigger Transaction Types
This setting controls bi-directional ("ping-pong") blocking for the publisher. When a record is written into a system by a subscriber, the platform normally prevents a publisher from immediately sending that same record back out — otherwise two systems could bounce the same change back and forth indefinitely.
By default, this block applies to any recently-written record matching the same entity type, sub-type, primary key, and system — regardless of transaction type. This is the safe default: it stops a save made under one transaction type from triggering an unrelated publisher of a different transaction type for the same record.
Occasionally that cross-transaction-type trigger is intentional — for example, a save under one transaction type should legitimately cause a publish under another. List those other transaction types here to exclude their writes from this publisher's blocking check, allowing them to trigger it. The publisher's own transaction type is never listed (a record written under the same transaction type always blocks, which is the core self-loop guard). Leave this empty unless you specifically need a cross-transaction-type trigger.
See Also
- Scheduling & Automation — Configure when publishers run and set up filters
- Key Scraping — Configure how primary keys are indexed after saves
- Endpoint Configuration — Configure endpoint action inputs
- Action Mapping — Map endpoint actions to Common Model properties